一、模型部署与推理
llama.cpp可以量化模型解决模型在电脑上跑不动的问题,而ollama则是解决量化后的模型怎么更方便的跑起来的问题。
HuggingFace (HF)

用于文本生成推理的 Rust、Python 和 gRPC 服务器。 在 HuggingFace 的生产中用于为LLM API 推理小部件提供支持。
HF文本生成推理的使用方法如下:
- 使用 docker 运行 Web 服务器
mkdir data
docker run --gpus all --shm-size 1g -p 8080:80 \
-v data:/data ghcr.io/huggingface/text-generation-inference:0.9 \
--model-id huggyllama/llama-13b \
--num-shard 1
发送请求:
# pip install text-generation
from text_generation import Client
client = Client("http://127.0.0.1:8080")
prompt = "Funniest joke ever:"
print(client.generate(prompt, max_new_tokens=17 temperature=0.95).generated_text)
HF文本生成推理的杀手级功能包括:
- 内置 Prometheus 指标 - 你可以监控服务器负载并深入了解其性能。
- 使用 flash-attention(和 v2)和分页注意力进行推理的优化转换器代码。 值得一提的是,并非所有模型都内置对这些优化的支持。 如果你使用不太常见的架构,可能会面临挑战。
Llama.cpp
LLaMA.cpp 项目是开发者 Georgi Gerganov 基于 Meta 释出的 LLaMA 模型(简易 Python 代码示例)手撸的纯 C/C+- 版本,用于模型推理。所谓推理,即是给输入-跑模型-得输出的模型运行过程。
那么,纯 C/C+- 版本有何优势呢?
- 无需任何额外依赖,相比 Python 代码对 PyTorch 等库的要求,C/C+- 直接编译出可执行文件,跳过不同硬件的繁杂准备;
- 支持 Apple Silicon 芯片的 ARM NEON 加速,x86 平台则以 AVX2 替代;
- 具有 F16 和 F32 的混合精度;
- 支持 4-bit 量化;
- 无需 GPU,可只用 CPU 运行;
- …
ollama
Ollama是一个开源的大型语言模型服务,提供了类似OpenAI的API接口和聊天界面,可以非常方便地部署最新版本的GPT模型并通过接口使用。支持热加载模型文件,无需重新启动即可切换不同的模型。
-
Ollama的优势
- 提供类似OpenAI的简单内容生成接口,极易上手使用
- 类似ChatGPT的的聊天界面,无需开发直接与模型聊天
- 支持热切换模型,灵活多变
搭建步骤
- 一键安装
使用提供的安装脚本一键安装Ollama - 准备模型
从网上获取已训练好的中文GPT模型。推荐使用llama-cpp转换后的gguf格式的模型。 - 创建Ollama模型
使用ollama create命令创建指向模型文件的Ollama模型 - 通过API测试
使用简单的文本接口测试模型 - 运行聊天界面
一键运行前端界面,与模型聊天
通过简单的步骤就可以搭建一个功能强大的中文AI应用。
使用场景
- 聊天机器人
- 文本生成
- 问答系统
总结
Ollama为我们带来了类似OpenAI的中文AI体验,简单易用,支持热切换模型,推荐所有中文AI开发者使用。
Llama.cpp
- llama.cpp 是GGML作者创始开发的一款纯C/C++的模型推理引擎,支持量化推理,支持多种设备、操作系统,最早是为了支持llama的推理,现在已经支持主流的开源模型。
- llama.cpp 的一个显著特点是其对硬件的高效利用。无论是Windows/Linux用户还是macOS用户,都可以通过编译优化来提高模型推理的速度。对于Windows/Linux用户,推荐与BLAS(或cuBLAS如果有GPU)一起编译,可以显著提升prompt处理速度。而macOS用户则无需额外操作,因为llama.cpp 已对ARM NEON做优化,并且已自动启用BLAS。M系列芯片推荐使用Metal启用GPU推理,以显著提升速度。
- llama.cpp 支持在本地CPU上部署量化后的模型,也就是结合上面提到的GGML,这样在超低配的硬件也能运行LLM。
vllm
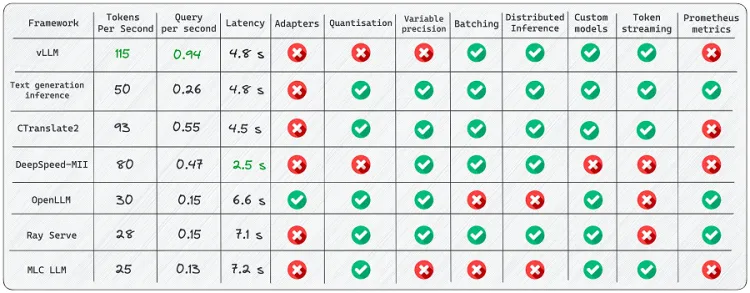
 vLLM是快速且易于使用的 LLM 推理和服务库。 它的吞吐量比 HuggingFace Transformers (HF) 高 14 倍至 24 倍,比 HuggingFace 文本生成推理 (TGI) 高 2.2 倍 - 2.5 倍。
vLLM是快速且易于使用的 LLM 推理和服务库。 它的吞吐量比 HuggingFace Transformers (HF) 高 14 倍至 24 倍,比 HuggingFace 文本生成推理 (TGI) 高 2.2 倍 - 2.5 倍。
vLLM的使用方法如下:
- 离线批量推理:
# pip install vllm
from vllm import LLM, SamplingParams
prompts = [
"Funniest joke ever:",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.95, top_p=0.95, max_tokens=200)
llm = LLM(model="huggyllama/llama-13b")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
- API服务:
# Start the server:
python -m vllm.entrypoints.api_server --env MODEL_NAME=huggyllama/llama-13b
# Query the model in shell:
curl http://localhost:8000/generate \
-d '{
"prompt": "Funniest joke ever:",
"n": 1,
"temperature": 0.95,
"max_tokens": 200
}'
vLLM的杀手级功能包括:
- 连续批处理 - 迭代级调度,其中批大小由每次迭代确定。 由于批处理,vLLM 可以在繁重的查询负载下正常工作。
- PagedAttention — 注意力算法的灵感来自于操作系统中虚拟内存和分页的经典思想。 这是模型加速的秘诀。
虽然vLLM库提供了用户友好的特性和广泛的功能,但我遇到了一些限制:
- 添加自定义模型:虽然可以合并你自己的模型,但如果模型不使用与 vLLM 中现有模型类似的架构,则过程会变得更加复杂。 例如,我遇到了添加 Falcon 支持的 Pull 请求,这似乎非常具有挑战性。
- 缺乏对适配器(LoRA、QLoRA 等)的支持:开源 LLM 在针对特定任务进行微调时具有重要价值。 然而,在当前的实现中,没有单独使用模型和适配器权重的选项,这限制了有效利用此类模型的灵活性。
- 缺乏权重量化:有时,LLM 可能不适合可用的 GPU 内存,因此减少内存消耗至关重要。
vLLM是 LLM 推理最快的库。 由于其内部优化,它的性能显着优于竞争对手。 然而,它确实存在支持有限模型的弱点。
Fastllm
fastllm是一个基于量化技术的大模型推理加速工具,通过降低模型参数的精度,可以在保证模型性能的同时减少推理所需的计算资源和内存占用。以下是使用fastllm的基本步骤:
- 安装fastllm库:从GitHub上克隆fastllm的仓库,并按照官方文档进行安装。
- 加载预训练模型:使用fastllm提供的API加载你想要加速的LLM模型。
- 模型量化:调用fastllm的量化函数对模型进行量化,选择合适的量化位数以达到最佳性能和速度的平衡。
- 推理:使用量化后的模型进行推理,你将发现推理速度和内存占用都得到了优化。
FastChat
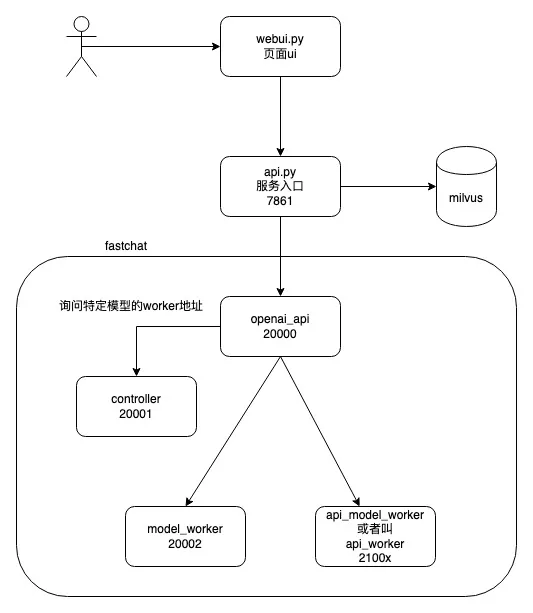
- FastChat是一个用于训练、服务和评估基于聊天机器人的大型语言模型的开放平台。The core features include:
- The training and evaluation code for state-of-the-art models (e.g., Vicuna).
- A distributed multi-model serving system with web UI and OpenAI-compatible RESTful APIs.
OpenLLM

用于在生产中操作大型语言模型 (LLM) 的开放平台。
OpenLLM的使用方法如下:
- 运行网络服务器:
pip install openllm scipy
openllm start llama --model-id huggyllama/llama-13b \
--max-new-tokens 200 \
--temperature 0.95 \
--api-workers 1 \
--workers-per-resource 1
发送请求:
import openllm
client = openllm.client.HTTPClient('http://localhost:3000')
print(client.query("Funniest joke ever:"))
OpenLLM的杀手级功能包括:
- 适配器支持 — 将多个适配器连接到仅一个已部署的 LLM。 试想一下,您可以仅使用一种模型来完成多项专门任务。
- 运行时实现 - 使用不同的实现:Pytorch (pt)、Tensorflow (tf) 或 Flax (flax)。
HuggingFace 代理 — 连接 HuggingFace 上的不同模型并使用 LLM 和自然语言对其进行管理。
OpenLLM的优点:
- 良好的社区支持——该库正在不断开发和添加新功能。
- 集成新模型 - 开发人员提供了有关如何添加自己的模型的指南。
- 量化 — OpenLLM 支持使用位和字节以及 GPTQ 进行量化。
- LangChain 集成 — 你可以使用 LangChian 与远程 OpenLLM 服务器交互。
OpenLLM的局限性:
- 缺乏批处理支持 - 对于大量消息流,这很可能成为应用程序性能的瓶颈。
- 缺乏内置的分布式推理——如果你想在多个 GPU 设备上运行大型模型,需要另外安装 OpenLLM 的服务组件 Yatai。
这是一个很好的框架,具有广泛的功能。 它使你能够以最少的费用创建灵活的应用程序。 虽然文档中可能未完全涵盖某些方面,但当你深入研究此库时,可能会发现其附加功能中的惊喜。
二、模型量化
- 模型训练时为了进度,采用的32位浮点数,因此占用的空间较大,一些大的模型需要很大的显存才能加载,且计算推理过程较慢。为了减少内存占用,提升推理速度,可以将高精度的参数转为低精度的参数,例如从 32 位的浮点数转换为 8 位整数,这个技术就叫做模型量化。
- 模型量化是一种将浮点计算转成低比特定点计算的技术,可以有效的降低模型计算强度、参数大小和内存消耗,但往往带来巨大的精度损失。尤其是在极低比特(<4bit)、二值网络(1bit)、甚至将梯度进行量化时,带来的精度挑战更大。
量化带来的好处
- 保持精度:量化会损失精度,这相当于给网络引入了噪声,但是神经网络一般对噪声是不太敏 感的,只要控制好量化的程度,对高级任务精度影响可以做到很小。
- 加速计算:传统的卷积操作都是使用FP32浮点,低比特的位数减少少计算性能也更高,INT8 相 对比 FP32 的加速比可达到3倍甚至更高
- 节省内存:与 FP32 类型相比,FP16、INT8、INT4 低精度类型所占用空间更小,对应存储空间 和传输时间都可以大幅下降。
- 节能和减少芯片面积:每个数使用了更少的位数,做运算时需要搬运的数据量少了,减少了访 存开销(节能),同时所需的乘法器数目也减少(减少芯片面积)
量化的方法与原理
主要有三种量化方法:
- 量化训练 (Quant Aware Training, QAT)
- 量化训练让模型感知量化运算对模型精度带来的影响,通过 finetune 训练降低量化误差。
- 动态离线量化 (Post Training Quantization Dynamic, PTQ Dynamic)
- 动态离线量化仅将模型中特定算子的权重从FP32类型映射成 INT8/16 类型。
- 静态离线量化 (Post Training Quantization Static, PTQ Static)
- 静态离线量化使用少量无标签校准数据,采用 KL 散度等方法计算量化比例因子
FP16/INT8/INT4
在huggingface上去查看模型时,会看到一些带有fp16、int8、int4 后缀的模型,比如Llama-2-7B-fp16、chatglm-6b-int8、chatglm2-6b-int4,其实这些模型就是量化后的模型,fp16表示模型的量化精度。
- FP32(单精度浮点数):使用32位二进制表示,其中1位用于sign,8位用于exponent,23位用于fraction。其数值范围大约是1.18e-38到3.40e38,精度大约是6到9位有效数字
- FP16(半精度浮点数):使用16位二进制表示,其中1位用于sign,5位用于exponent,10位用于fraction。其数值范围为[5.96×10^-8, 65504],但实际能表示的最大正值为65504,最小正值约为0.0000000596(非规格表示下),符号位为0时代表正数
- INT8,八位整型占用1个字节,INT8是一种定点计算方式,代表整数运算,一般是由浮点运算量化而来。在二进制中一个“0”或者“1”为一bit,INT8则意味着用8bit来表示一个数字
- int4占用4个字节(32位)
量化精度从高到低排列顺序是:fp16>int8>int4,量化的精度越低,模型的大小和推理所需的显存就越小,但模型的能力也会越差。
业界有一些开源的量化模型格式,下面来介绍。
GGML
https://github.com/ggerganov/ggml
GGML全称是Georgi Gerganov Machine Learning,是由Georgi Gerganov开发的一个张量库(tensor library),Georgi Gerganov开源项目llama.cpp的创始人。
GGML是一个C写的库,可以将LLM转为为GGML格式,通过量化等技术让LLM方便进行加载和推理
- 采用量化技术,将原有大模型预训练结果量化(即将原有大模型FP16精度压缩成INT8、INT6精度
- 二进制文件编码,将量化后的预训练结果通过一种指定的格式变成一个二进制文件
特性:
- 用 C 语言编写
- 支持 16 位浮点数
- 支持整数量化(4 位、5 位、8 位等)
- 自动微分
- ADAM 和 L-BFGS 优化器
- 针对 Apple 芯片进行了优化
- 在 x86 架构上利用 AVX/AVX2 内在函数
- 在 ppc64 架构上利用 VSX 内在函数
- 无第三方依赖项
- 运行时不进行内存分配
在 HuggingFace 上,如果看到模型名称带有GGML字样的,比如Llama-2-13B-chat-GGML,说明这些模型是经过 GGML 量化的。有些 GGML 模型的名字除了带有GGML字样外,还带有q4、q4_0、q5等,比如Chinese-Llama-2-7b-ggml-q4,这里面的q4其实指的是 GGML 的量化方法,从q4_0开始往后扩展,有q4_0、q4_1、q5_0、q5_1和q8_0,在这里可以看到各种方法量化后的数据。
GGUF
GGML是基础的文件格式,没有版本控制或数据对齐,适用于不需要考虑文件版本兼容性或内存对齐优化的场景。2023年8月份,Georgi Gerganov创建一个新的大模型文件格式GGUF,全称GPT-Generated Unified Format,用以取代GGML格式。GGUF 与 GGML 相比,GGUF 可以在模型中添加额外的信息,而原来的 GGML 模型是不可以的,同时 GGUF 被设计成可扩展,这样以后有新功能就可以添加到模型中,而不会破坏与旧模型的兼容性。
但这个功能是Breaking Change,也就是说 GGML 新版本以后量化出来的模型都是 GGUF 格式的,这意味着旧的 GGML 格式以后会慢慢被 GGUF 格式取代,而且也不能将老的 GGML 格式直接转成 GGUF 格式。
GPTQ
GPTQ 是一种模型量化的方法,可以将语言模型量化成 INT8、INT4、INT3 甚至 INT2 的精度而不会出现较大的性能损失,在 HuggingFace 上如果看到模型名称带有GPTQ字样的,比如Llama-2-13B-chat-GPTQ,说明这些模型是经过 GPTQ 量化的。以Llama-2-13B-chat为例,该模型全精度版本的大小为 26G,使用 GPTQ 进行量化成 INT4 精度后的模型大小为 7.26G。
现在更流行的一个 GPTQ 量化工具是AutoGPTQ,它可以量化任何 Transformer 模型而不仅仅是Llama,现在 Huggingface 已经将 AutoGPTQ 集成到了 Transformers 中。
GPTQ vs GGML
GPTQ 和 GGML 是现在模型量化的两种主要方式,在实际运用中如何选择呢?
两者有以下几点异同:
- GPTQ 在 GPU 上运行较快,而 GGML 在 CPU 上运行较快
- 同等精度的量化模型,GGML 的模型要比 GPTQ 的稍微大一些,但是两者的推理性能基本一致
- 两者都可以量化 HuggingFace 上的 Transformer 模型
因此,如果目标模型是在 GPU 上运行,那么优先使用GPTQ 进行量化,如果你的模型是在 CPU 上运行,那么建议使用 GGML 进行量化