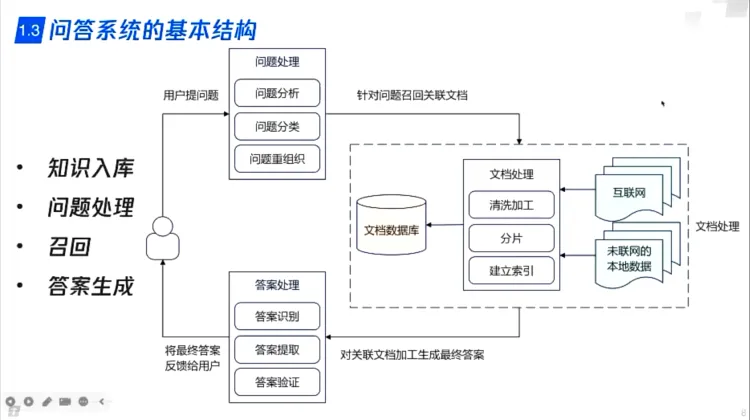
问答系统基本结构:
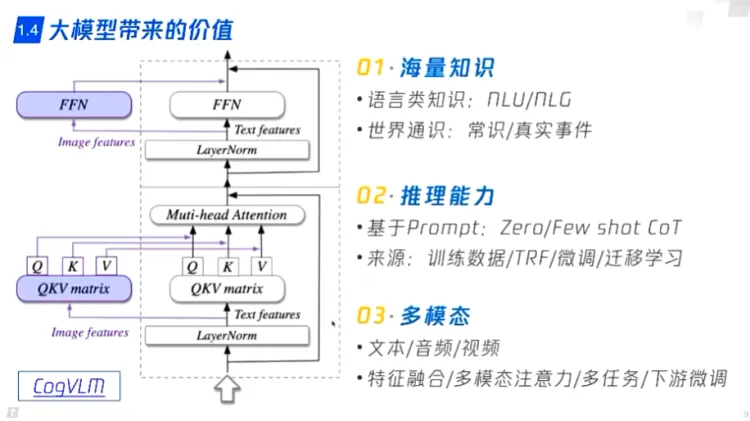
大模型带来的价值:
- 通识知识
- 推理能力
- 多模态数据处理
大模型的局限:
- 垂直领域知识没有,知识更新慢
- 没有小模型的专业能力
- 幻觉

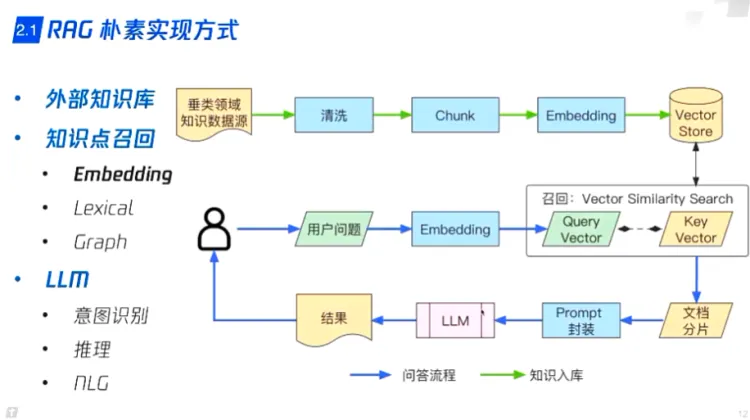
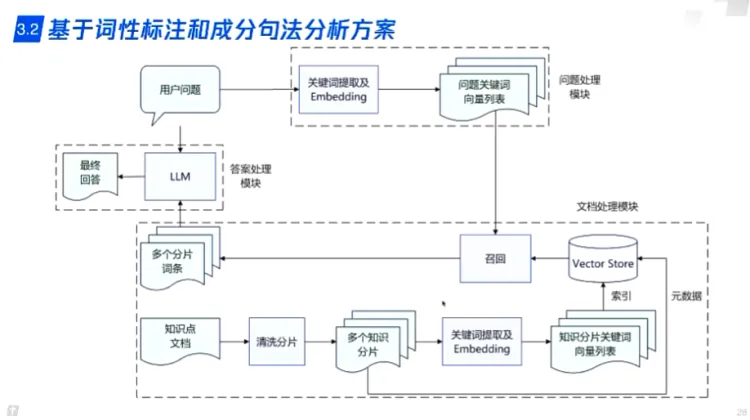
RAG技术方案 - Embedding召回:
- embedding 召回内容块
- LLM功能:
- 意图识别
- 推理,总结
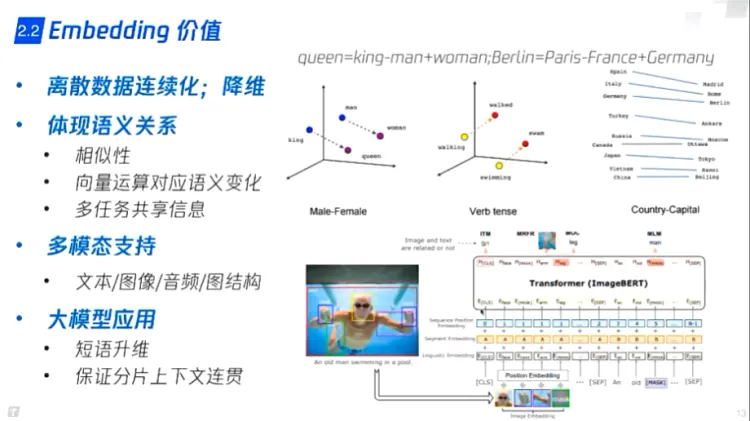
embedding 好处:
- 将维度降低
- 可以体现部分语义关系
- 多模态数据可以统一表征
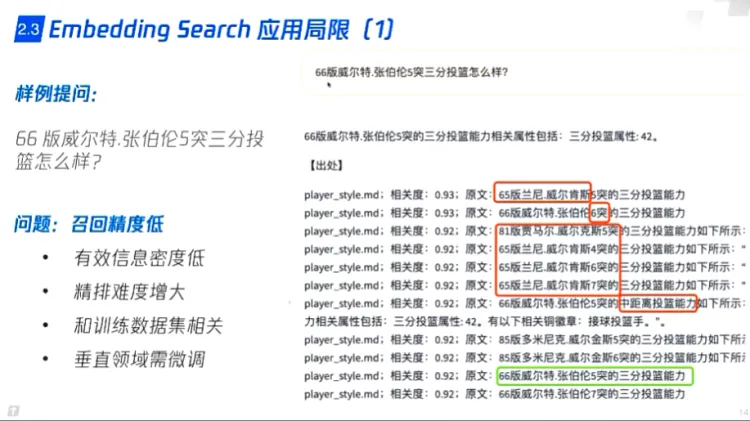
embedding 局限:
一些问题
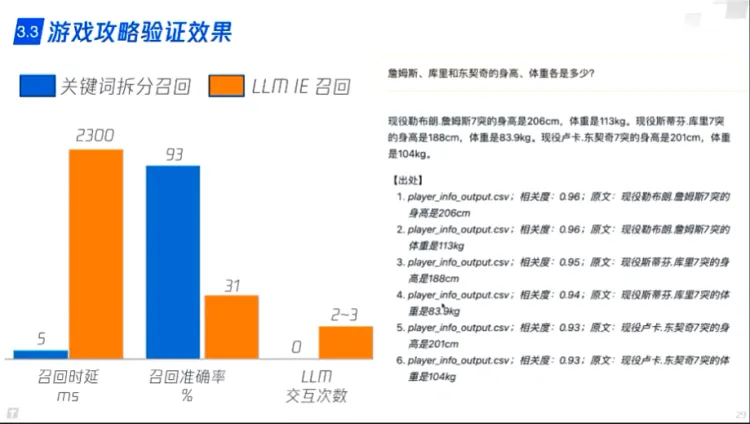
1. **召回精度低** -> 有效信息密度低
2. **粒度过粗** -> token浪费,影响LLM处理速度和精度
3. **不能替代信息提取** -> 实体/关系/事件,条件/统计查询,外部工具链使用(推荐服务),不适合任务式对话(调用API并补全参数)
4. **上下文支持有限 **-> 分片粒度选择,如何避免信息丢失,如何召回上下文
5. excel 数据很难处理和推理(设计提问补全?)
可能的解决方案:
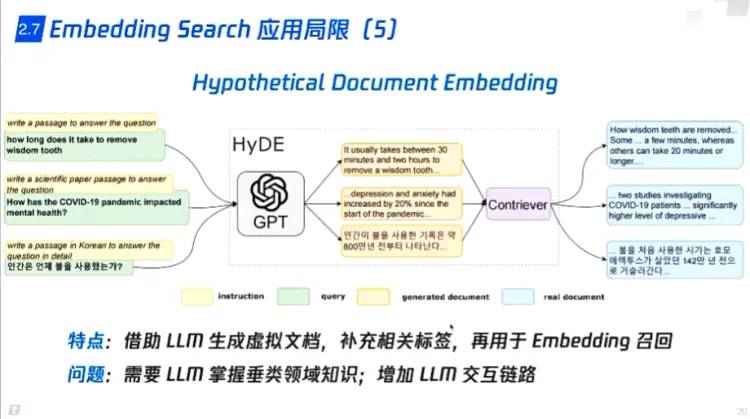
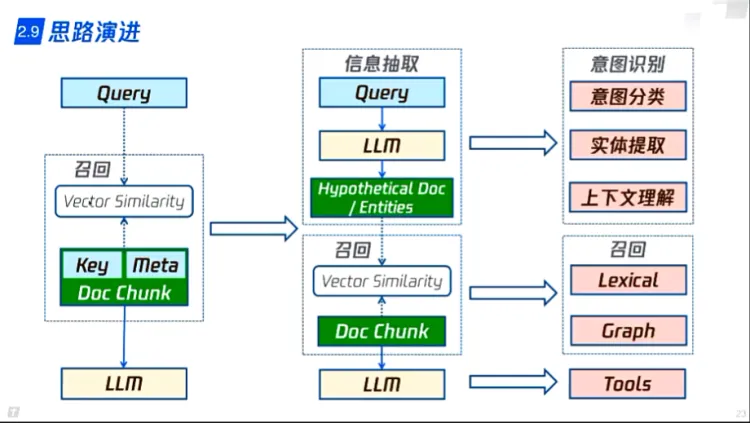
1. LLM生成虚拟文档,扩充问题,再用于embedding召回
1. 会增加时间和调用开销
2. LLM需要微调,做垂类
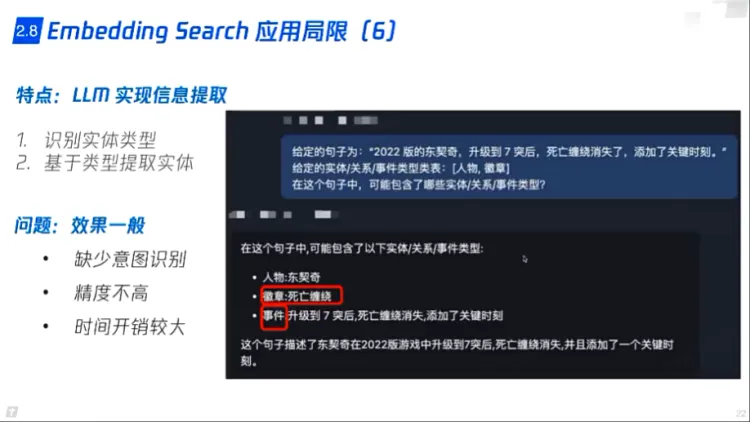
2. LLM实现信息提取:识别实体类型,基于类型提取实体
1. 效果一般
2. 缺少意图识别
3. 精度不高
4. 时间开销大




RAG技术方案优化 - 意图识别优化:
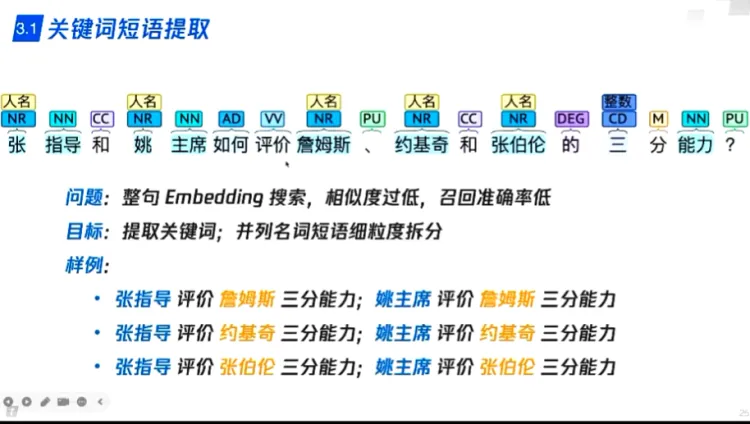
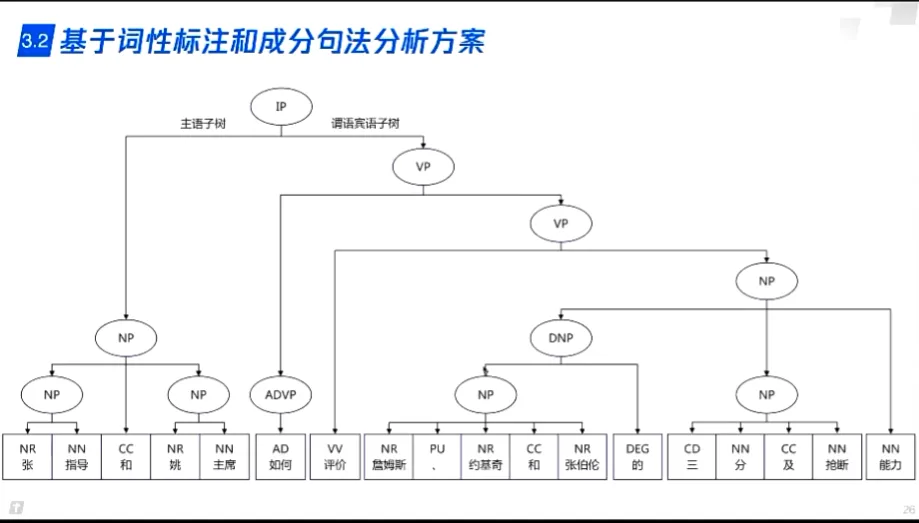
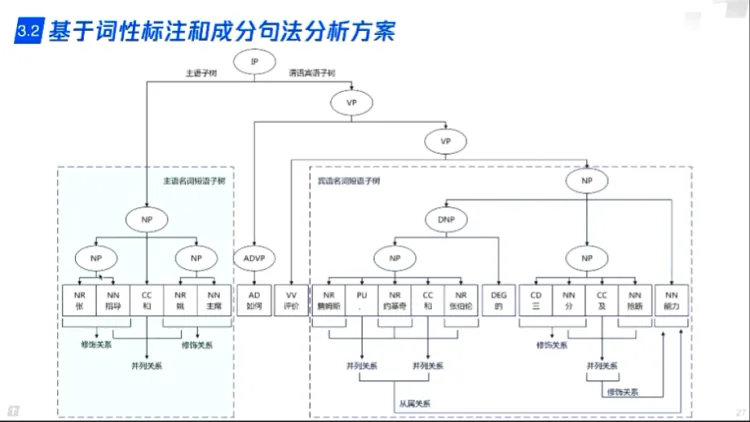
传统方案 - 基于词性标注和句法分析
- 传统NLP技术可以实现并列,从属等关系,实现问题补全扩充
- 没有意图并不能帮助理解用户问题
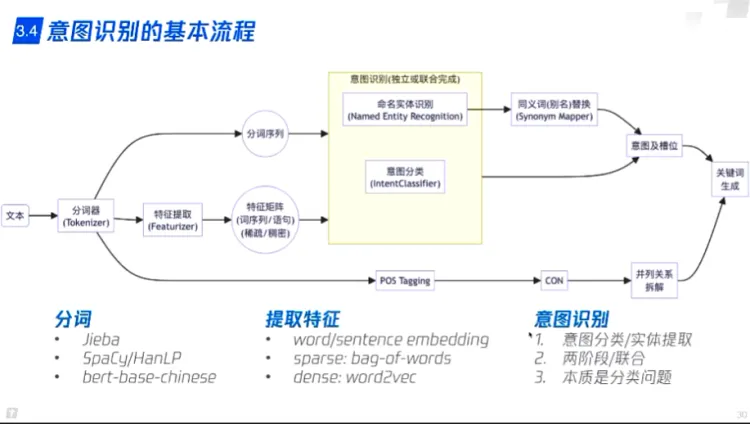
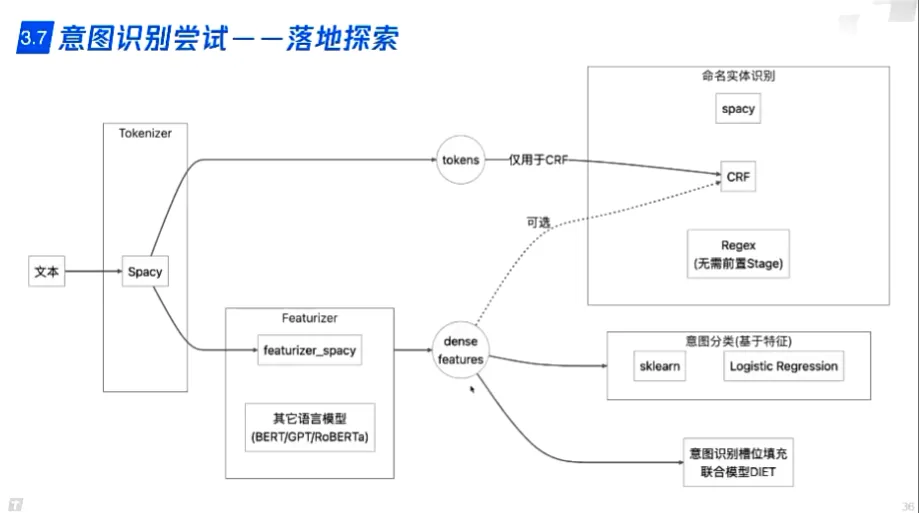
传统方案 - 意图分类+命名实体识别
- 单轮对话
- 意图分类(BERT/DIET),提供槽位
- 命名实体识别(BERT/DIET),填充槽位
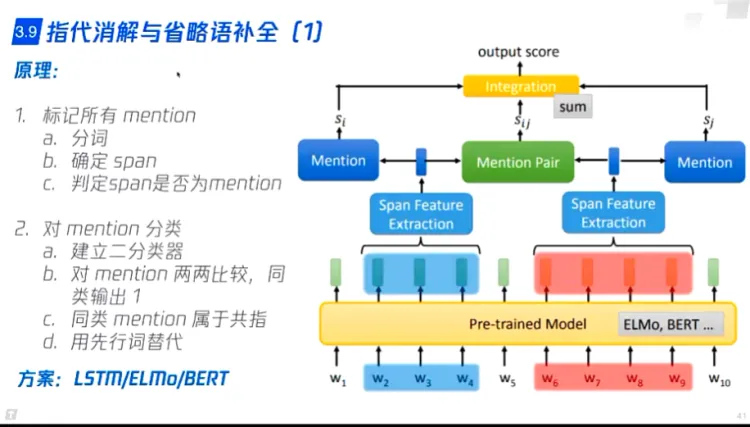
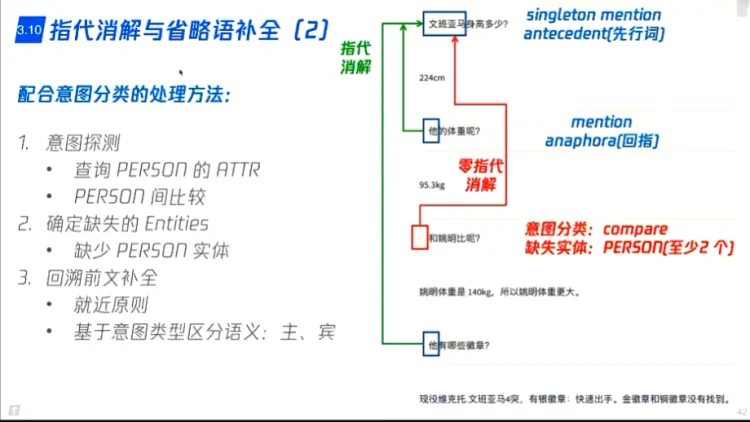
- 指代消解与省略语补全(LSTM/ELMo/BERT)分类问题
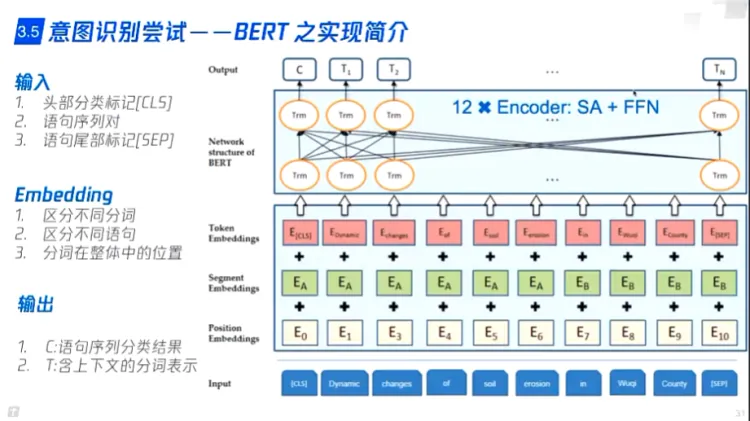
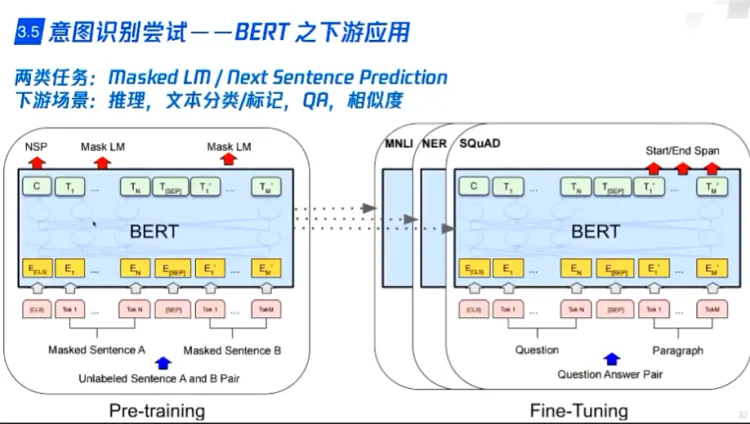
- BERT
- BERT提供CLS头部分类标记,需要与业务对接进行finetune,实现具体分类
- BERT对此进行mask,实现实体实体
- BERT同时实现意图预测和命名实体识别,联合训练
- 训练开销大
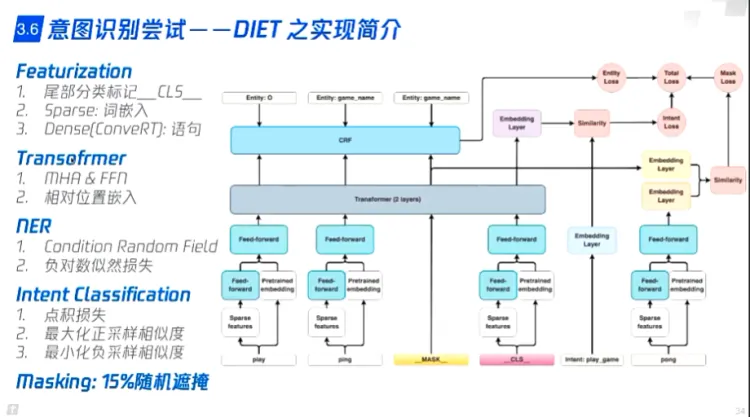
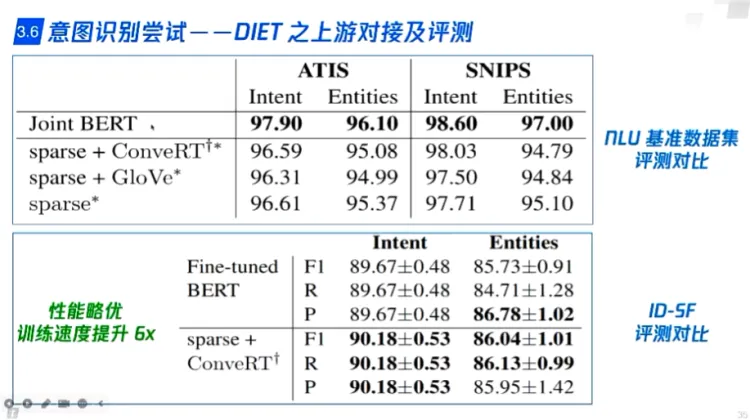
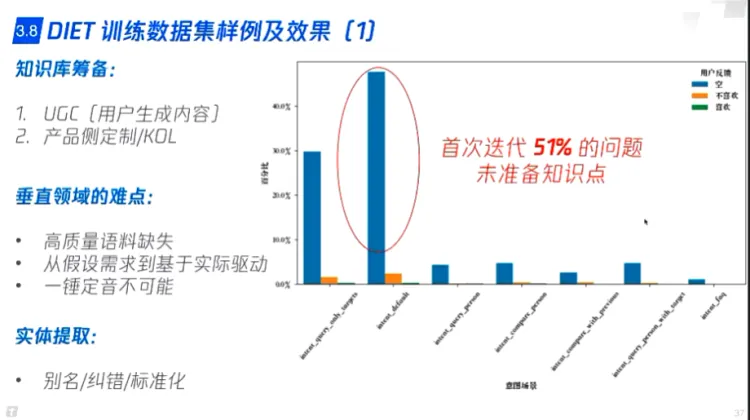
- DIET(rasa)
- 根据用户数据迭代
- 数据集准备
- 专业名词替换
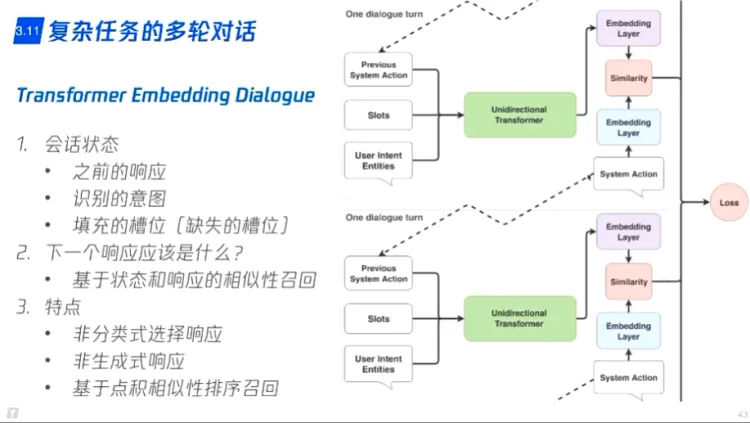
- 复杂任务的多轮对话
- 根据意图,把缺失信息提问
- 分类式响应:预定义一些问题
- 生成式响应:通过相似性排序





RAG技术方案优化 - 检索优化:
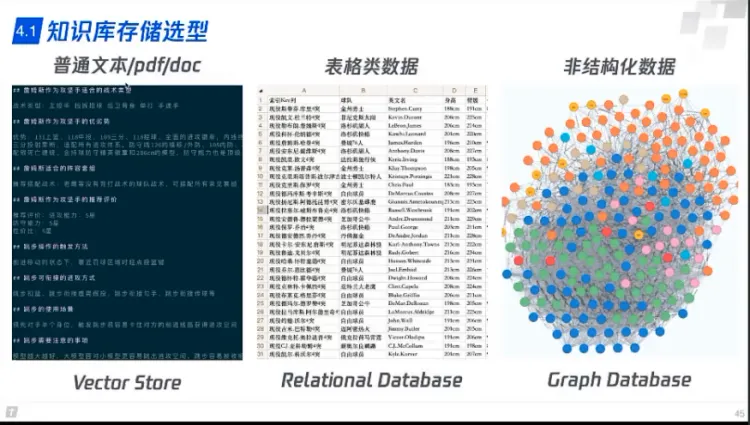
知识库
- 向量库
- 普通文本
- doc
- 关系数据库
- 表格类数据
- 图数据库
- 非结构化数据
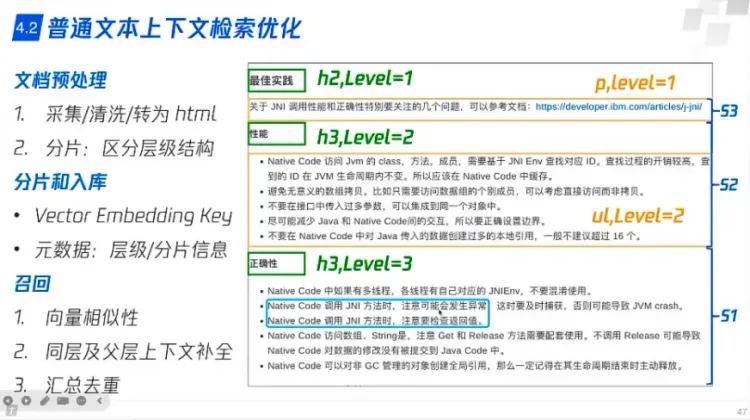
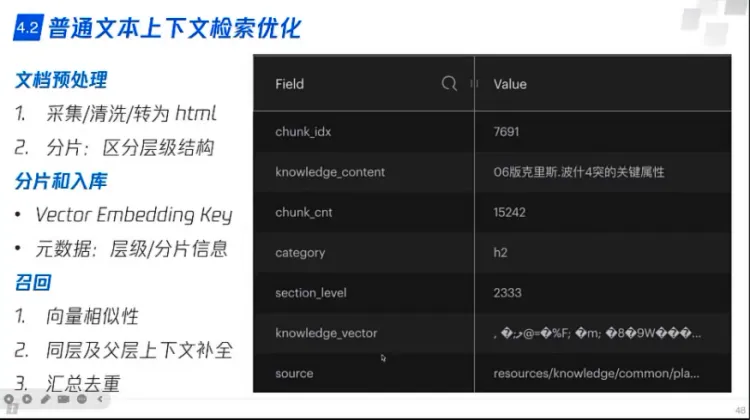
普通文本检索优化
- 文档预处理
- 采集/清洗/转为html
- 分片,分层级
- 分片和入库
- 给出chunk id 等等用于其他算法
- 召回
结构化数据检索
- 数据格式转为 panda dataframe / SQL
- 理解用户问题,生成code,去跑工具
- Prompt:CoT
- 依赖LLM性能,要做降级处理
- Text2SQL
- 获取数据表
- 生成Prompt
- 结果提取
- 业务层校验
- 成功率比较低 < 40%(SFT结果不一定好)
- 基于规则生成 SQL,pandas
- 看业务,场景少可以用
- 枚举
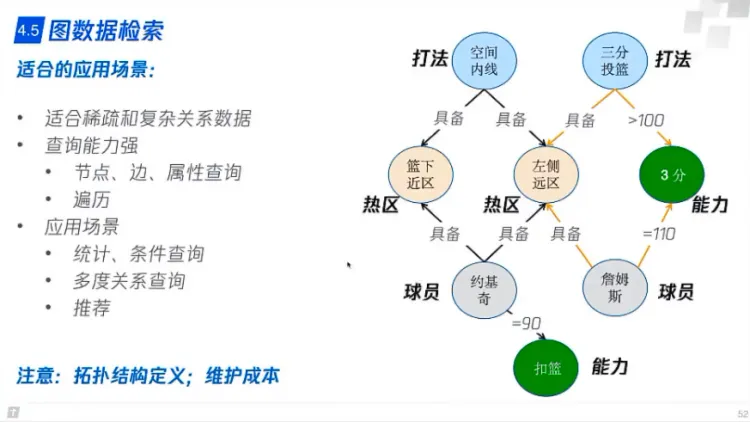
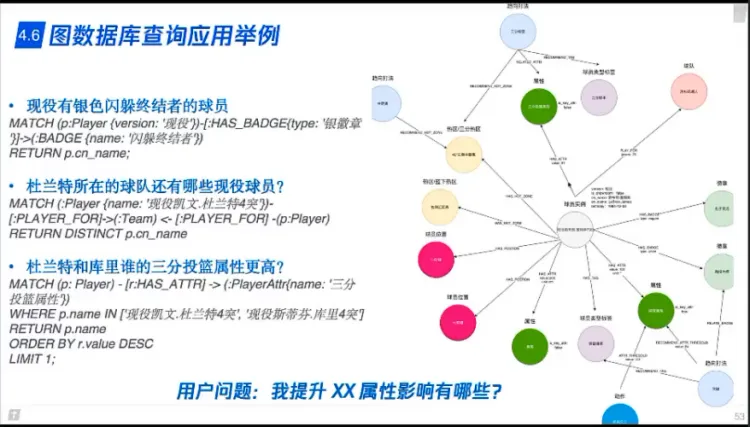
图数据检索
- 适合的应用场景
- 适合稀疏和复杂关系(多步关系)数据
- 做推荐




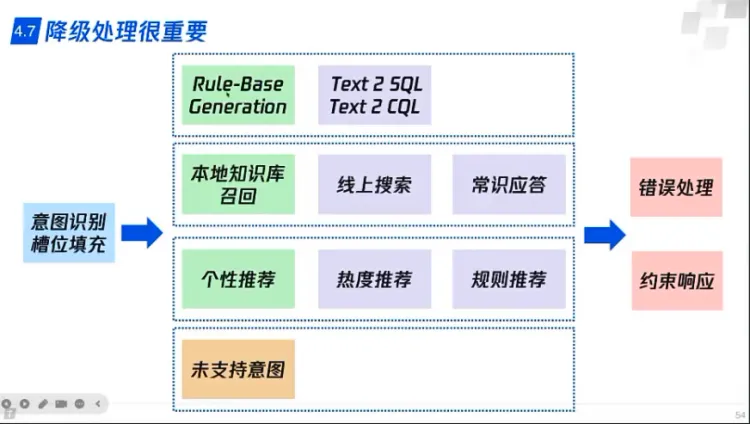
RAG技术方案优化 - 降级处理:

RAG技术方案优化 - Agent(以业务为中心):
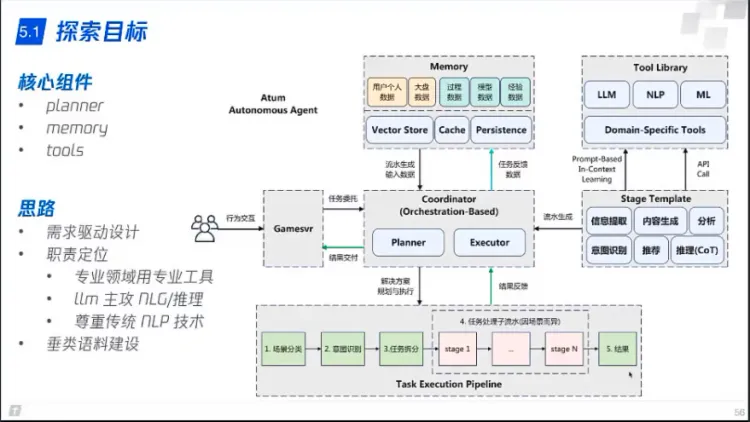
需求驱动
1. 业务为中心,开发组件,LLM也是一个组件
2. LLM主攻NLG和推理
3. 垂类语料建设