基于LangChain+LLM的本地知识库问答:从企业单文档问答到批量文档问答_langchain 本地知识库-CSDN博客
参考文献
https://github.com/datawhalechina/hugging-llm https://github.com/datawhalechina/llm-universe https://github.com/milvus-io/milvus https://github.com/chatchat-space/Langchain-Chatchat https://www.milvus-io.com/integrate_with_langchain https://blog.csdn.net/liluo_2951121599/article/details/134229683 https://cloud.tencent.com/developer/article/2302432 https://www.aliyun.com/activity/bigdata/opensearch/llmsearch https://zhuanlan.zhihu.com/p/641132245 https://zhuanlan.zhihu.com/p/364923722 https://zhuanlan.zhihu.com/p/644603736
现成产品
一些坑
- 直接上传数据库就算能成功效果也很差,目前最佳实践还是人工来进行预处理
分成多个很小的markdown格式化文件,效果最好
实现原理
- 加载本地文档
- 文本拆分
- Embedding
- ernie
- text2vec
- m3e
- bge
- piccolo
- 根据提问匹配文本(向量数据库)
- 字符匹配(类关键词)
- 语义检索
- 构建Prompt
- Prompt engineering
- LLM生成回答
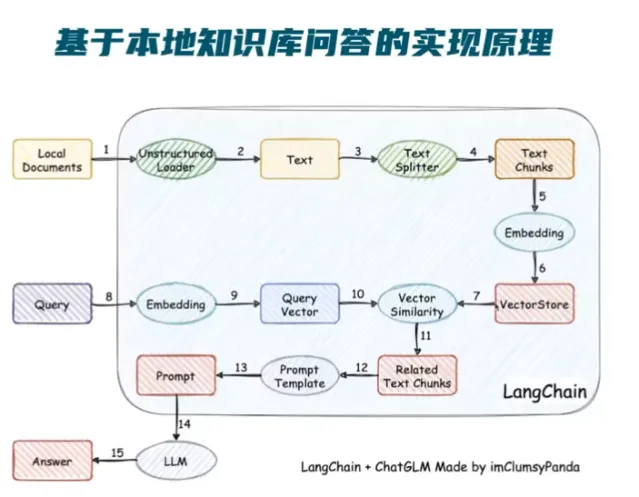
微调和提示词工程
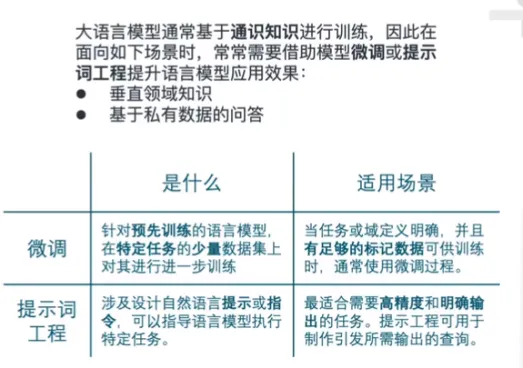
LangChain介绍

LangChain 应用场景
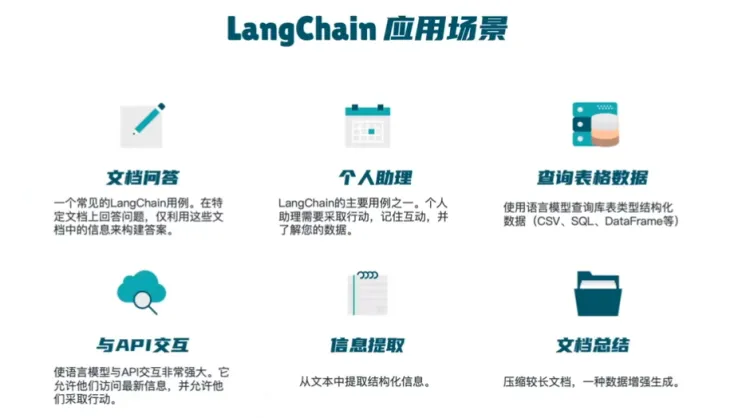
如何实现基于本地知识的问答

效果优化方向
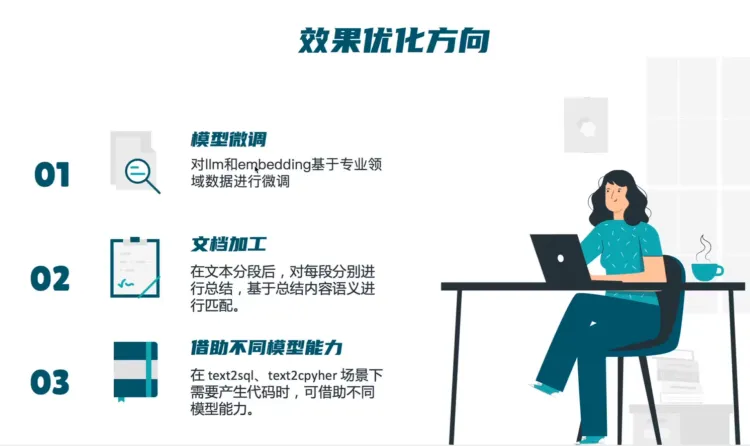
改进思路
《基于智能搜索和大模型打造企业下一代知识库》之《典型实用场景及核心组件介绍》 | Amazon Web Services
如何用大语言模型构建一个知识问答系统-腾讯云开发者社区-腾讯云
【大模型应用开发教程】04_大模型开发整体流程 & 基于个人知识库的问答助手 项目流程架构解析-CSDN博客
大模型RAG检索增强问答如何评估:噪声、拒答、反事实、信息整合四大能力评测任务探索 - 智源社区
- 需要结合传统NLP,做意图理解(NLU),降级处理(异常处理),否则无法保证鲁棒性
- 数据预处理成html,做分级,检索时根据需要取高一级的内容
- nougat-ocr,ocr需要优化