问题陈述
还是DiSCO的实验,DiSCO的预处理涉及到大量的点云转polar BEV的计算,这个过程是具有并行性的,因此之前写论文的时候用到了CUDA+Cython加速。CUDA部分是用来计算点云中每个点在polar BEV中的坐标值,C++根据CUDA中计算的坐标值将对应的点信息重新整理成polar BEV,Cython则是用来将C++的程序wrap成python中的module,整个过程就是这样。
接下来就是出现了问题。在我自己处理点云的时候,点云的规模一般在10w以下,因为是单帧的点云做Place recognition,单帧点云的规模顶多这个水平,大不了在voxelgrid 滤波一下。但是!师姐和我说跑出来Segmantation fault了,她觉得应该是点云规模太大了,70w的点不行,60w可以。我愿称师姐为测试一霸!
发现问题
首先想到的竟然是GPU难道不能支持这么多线程?我还是对GPU的能力产生了不切实际的怀疑,我的锅。
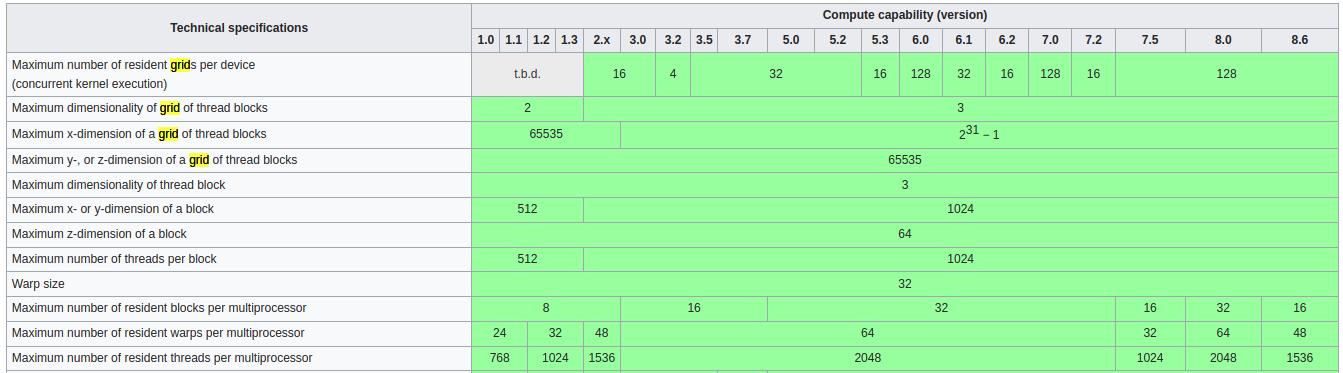
根据https://en.wikipedia.org/wiki/CUDA上的表格,我台式机RTX2060 Super的计算能力(Compute Capability)的version是7.5。对应表格中max grids per device 有 128个,对应每个grid,x维度有2147483647个thread blocks,每个blocks有1024个线程。好的,算都不用算肯定不是这个问题了。
那还能是啥呢,接下去看C++部分,cudaMalloc和cudaMemcpy都没报错,实际并行跑kernel程序也没问题。看来确实应该相信GPU。结果发现是在想要把数据从GPU拿回来的时候,申请了几个int [] 的问题。大概是3个 int [&{input size}],这竟然申请不下来。int 4字节,3×4×700000=8400000,8400000/1024/1024=8.011M。
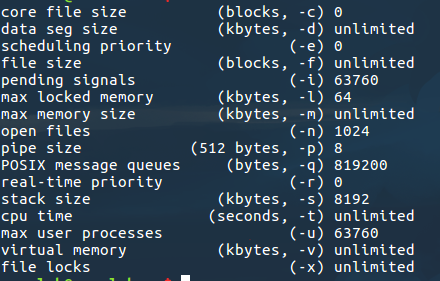
这让我想到了一年前曾经支配过我的栈内存问题,像这类局部变量是在栈内存上申请的,栈内存一般也就几M,所以就会segmentation fault了。在bash中 ulimit -a可以看系统资源,我的是8192=8M,之前申请的刚好超一丢丢。所以报错了。
解决问题
在bash中可以暂时通过 ulimit -s 来设置stack size,我将它设为 81920,就ok了。但是这只是暂时的方法,要想彻底解决这个问题,还是得从代码上,直接将所有操作放在gpu上进行计算,就不用通过c++来中间过渡了。