- 2017年底已经在 阿里云的 cpu服务器路上配置好了环境,同时在gpu实例上配置了环境并做成了相应的镜像DNN_GPU。
- 学习数据来源:Kaggle
- 学习教程网站:http://zh.gluon.ai/
Jupyter Book
- 指令:jupyter notebook –NotebookApp.contents_manager_class=’notedown.NotedownContentsManager’ –ip=0.0.0.0 –allow-root
Loss Function
-
交叉熵:常用于逻辑分类问题
-
单分类问题:每一个图像样本只有一个类别
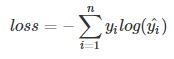
-
多分类问题:图像样本中可以有多个类别
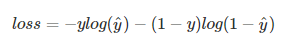
-
-
MSE(均方误差):常用于线性回归
超参数
- 神经网络的层数
- 隐藏层中隐藏单元的个数
- 权重衰减中:L2范数正则项中的 λ
- 丢弃法中:丢弃概率
Softmax回归
输出为离散值,为分类模型
- loss function为交叉熵
多层感知机
在单层神经网络的基础上引入了一个到多个隐藏层,且隐藏层输出上作用激活函数。
-
如果隐藏层为全连接层且为线性变换,则输入到输出经过两次仿射变换,但多个线性变换仍是一个线性变换,故加入隐藏层的效果等同于只有输出层的单层神经网络。
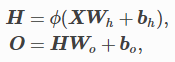
激活函数
加入非线性变换的元素
-
ReLU(Rectified Linear Unit):relu(x)=max(x,0)
-
Sigmoid:sigmoid(x)=1/(1+exp(-x))值域控制在0~1
-
Tanh:双曲正切
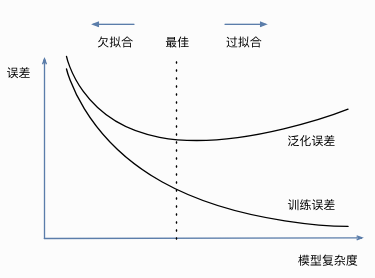
过拟合&欠拟合
欠拟合就是模型无法得到较低的训练误差;过拟合是指训练误差远小于它在测试集上的误差。
发生原因:
-
模型复杂度
-
训练数据集的大小
应对过拟合常用方法:
-
权重衰减==L2范数正则化:
在原loss函数基础上加入L2范数正则项
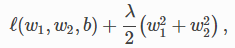
当λ较大时,惩罚项在损失函数中的比重较大,这会使得学到的权重参数(w1,w2)元素较接近0
-
丢弃法:
隐藏层的隐藏单元有一定的概率被丢弃。一般不使用丢弃法。
应对训练数据集较小的情况:
-
K折交叉验证:
把原始训练数据集分割成K个不重合的子数据集,然后做K次模型训练和验证,每次的训练集和验证集都不同,最后对这K次训练误差和验证误差求平均就可以得到较为准确的结果。(K一般为5、10)
离散型特征处理
- One-hot encoding:独热码,多少个状态就有多少个比特表示,即编码使得每个特征用0,1表示